
EvalC3 Online: How to use the Select Data screen
What you can see
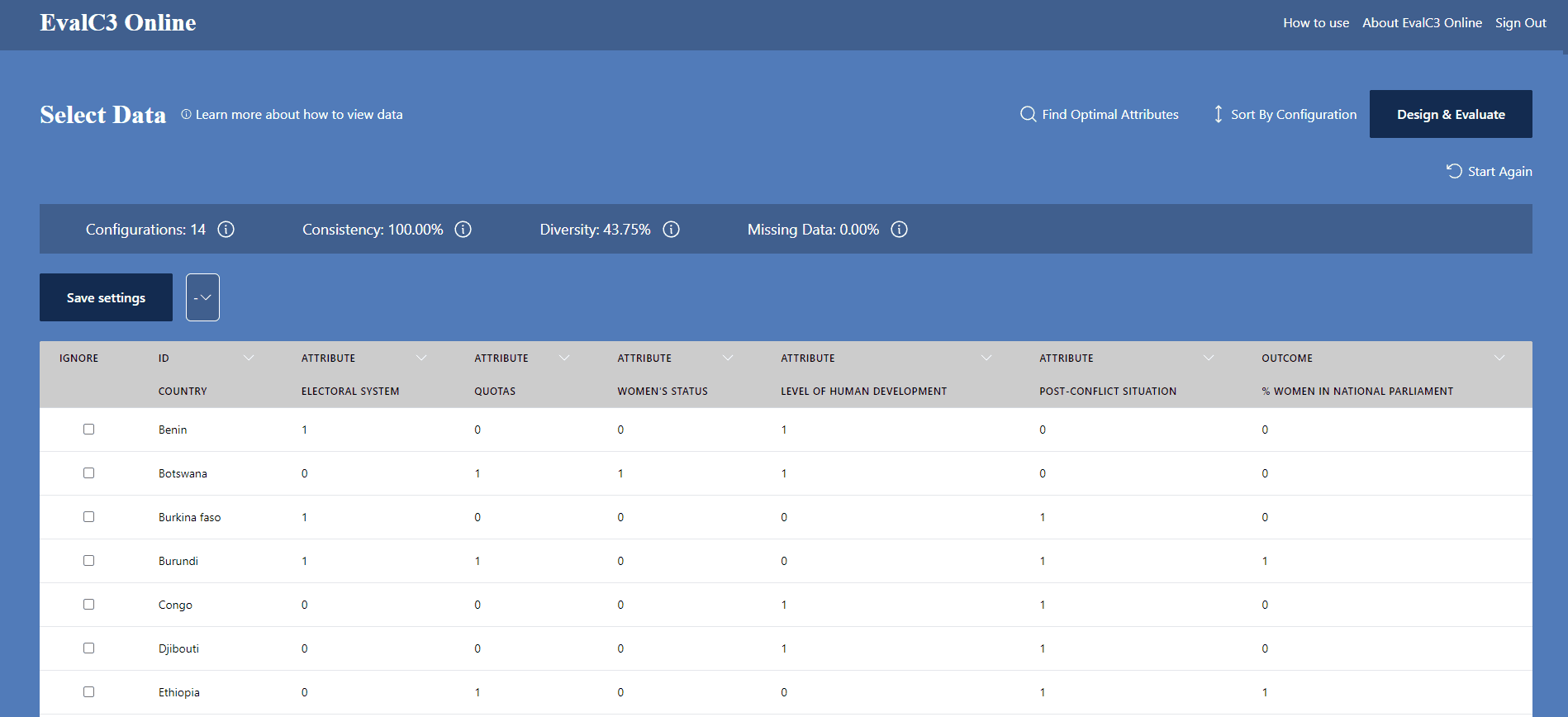
Across the top you can see five descriptive measures, describing the whole data set:
- Configurations: The number of different configurations of case attributes (excluding the Outcome). Cases with the same configuration of attributes can be made more visible by clicking on "Sort by Configuration". Each configuration will be in a distinct color band (blue or white)
- Consistency: The proportion of all configurations which each have consistent outcomes (i.e having all 0 or all 1 values)
- Diversity: The proportion of all possible configurations that are actually present in the data set, given the number of case attributes. The number of possible configurations = 2 to the power of N, where N = number of attributes.
- Balance: The percentage of cases with the outcome present [not yet visible but coming soon]
- Missing: The percentage of all data points with missing values
What you can do
Each column has been given a default label, which you may want to edit.
- At least one column needs to be labelled “ID”. Preferably one that tells you something about the identity of each case. The first column is by default labelled as ID. However, any column can be redesignated as ID.
- One and only one column needs to be labelled OUTCOME. It is events in this column that EvalC3 will try to predict. The last column is by default labelled as OUTCOME. If you have more than one column of outcome data in the data set you have chosen to use, label those outcome columns you will not use in any given analysis as ""IGNORE""
- All of the other columns will be by default be labelled as ATTRIBUTES. These will be used to develop a predictive model of the outcome. Any of these can be left out of a current analysis by changing their label to “Ignore”. Or you may want to change their status to OUTCOME.
After you have changed the labels of any of the columns, and want to go ahead with an analysis, click on Save Setting, and give a name to this setting. You can come back at any time and change these settings, and then save the new settings under a new name. The View Models view will include information on which settings were used to generate which models.
In the left most column, you can also click on selected cases that you want an analysis to ignore. Clicking on Save Setting will save this information along with any labels you have chosen to change.
Optimising the set of attributes – a non-essential function
You may want to do this if you have a data set with a large number of attributes. If you click on Find Optimal Attributes you will have three choices of how to find the optimal set of attributes within the existing data set, for further analysis:
- Consistency and Diversity: A search algorithm will find the highest possible combination of both values.
- Consistency: A search algorithm will find the highest possible consistency value. A predictive model found with this sub-set of attributes will have fewer problems of internal validity. You should set the maximum allowable number of attributes.
- Diversity: A search algorithm will find the highest possible diversity value. A predictive model found with this sub-set of attributes will have fewer problems of external validity. You should set the minimum allowable number of attributes.
The search algorithm findings will appear as a changed set of column labels
When all choices have been made about the status of each of the columns, and these settings saved, click on Design and Evaluate to proceed to that view.
Bear in mind that there are other ways of reducing the number of attributes being used. Most notably, a more theory-led approach, where the inclusion of relevant attributes is driven by a theory of some kind that suggests which attributes are likely to be most relevant.
