EvalC3 Online: How to use Search For New Models
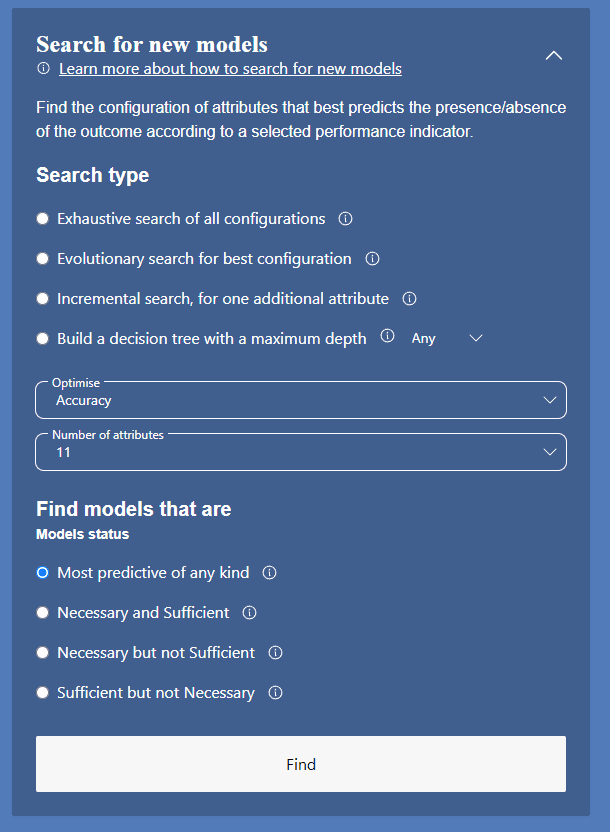
What you can see
In the panel on the bottom left labelled "Search for new models" click on the downward facing arrow to make a pop-up menu visible, as shown above.
At the top is a menu of four different types of search algorithms, each with an associated information balloon providing a short explanation.
The Decision Tree option has a setting, defining the depth of the tree. Its default is set at Any
Below that, in the middle, are two other settings. The first is the choice of performance measure that will be used to assess the results of each search. The default setting is Classification Accuracy. The second is the Number of Attributes, i.e. the maximum number of attributes any best performing model is allowed. Generally speaking, fewer is better.
Below these settings, at the bottom, are four alternate options for the kind of search result that is desired. The default / most commonly used would be the first i.e "Most Predictive of any kind"
What you can do
The problem: If a dataset has information on 10 different attributes of projects this means that there could be 2 to the power of 10 different combinations of these that might be the best predictor of an outcome of interest i.e. 1,024 possibilities. EvalC3 Online provides a number of ways of searching through these possibilities to find the most accurate predictor. They each have their strengths and weaknesses.
1. Hypothesis led manual selection of attributes, based on a theory derived from past experience and/or research elsewhere. The advantage of this approach is that where the hypothesis is correct there may already be good foundational knowledge, from prior research, on why it works. In EvalC3 Online a prediction model can be developed manually by choosing relevant values under Model Design menu. and then observing its performance. Normally this should be the first step in an analysis process using EvalC3. However it is possible that there are other solutions with an even better fit with the data, which lay out of sight outside our current understanding, as follows...
2. Incremental search. This is a step by step form of exhaustive search. There are two main ways of using it:
2.1 Where there is already an existing model the attributes of this model are treated as search constraints. An exhaustive search is then be made of x+1 attributes, where x is the number of attributes in the current model.
2.2 Where there is no existing model using the “incremental search” will search for the best performing single attribute model. This is useful when searching for single attributes that are necessary or sufficient for the outcome. If this search is re-iterated it will treat the result of the first search as a constraint that has to be met. The new model will have x + 1 attributes. Repeating this process will build up the model size, one attribute at a time.
3. There is a risk, that I have not substantiated, that this form of incremental search will get stuck in “local optimum“. There are two ways of checking if this is the case, which are valid search strategies in their own right:
3.1 Exhaustive search, where every possible combination of multiple attributes is examined. Because it is exhaustive the results will be conclusive. However, an exhaustive search can be very time consuming if there are many attributes (processing time doubles with each additional attribute in a data set). This problem can now be mitigated by specifying the maximum number of attributes in any model found by exhaustive search. I often try this search with a 3 or 4 attributes maximum
3.2 Evolutionary search. When data sets are large (deep and/or wide) an exhaustive search described above can be too slow to implement. Evolutionary searches are a very efficient means of searching for complex (i.e. multi-attribute) models within much larger combinatorial spaces. EvalC3 makes use of a genetic algorithm, to carry out evolutionary searches. However evolutionary searches are not necessarily as conclusive in their findings as exhaustive searches, because they sample different combinations of attributes, rather than test all of them. For this reason, the value of the results generated by an evolutionary search should be tested by repeating the search a number of times
4. Decision Tree searches provide another option: a way of generating a whole set of models, which best predict all outcomes, both present and absent. Decision Trees have their own risks, The best known is called "over-fitting". Over-fitting occurs when a Decision Tree models becomes so specific that it fails to generalise i.e it does not work when applied in other contexts. Over-specific in this context means having a large number of attbutes that define the model. There are two ways of addressing this problem.
4.1 As with the exhaustive search, it is possible to specify the depth of the tree in advance i.e. the maximum number of attributes in the models to be generated by this search.
4.2 After a Decision Tree is generated it is possible to manually examine each branch and see if can be simplified by removing some of later nodes, without having a big impact on the model's performance. This is a "pencil and paper" exercise, there no feature within EvalC3 Online that automates this step.
